Data Index
Data indices in Cafe Variome V4 are not just optimisation tools for querying; they are also a crucial part of the data model. Because the data model is dynamic and can be defined by the users, the data index serves as a way to specify how to display the data in the discovery interface, and letting other nodes know what data is available for sharing and how it can be queried.
A data index is a piece of instruction that tells the system how a field is intended to be queried and displayed. It includes information about the model this field belongs to, the path to the field within the model, and the type of the data. Note that the index type is not the raw data type -- a field may be of type integer, but the index may be enumerated if the field is intended to be queried as a categorical variable with a limited set of values.
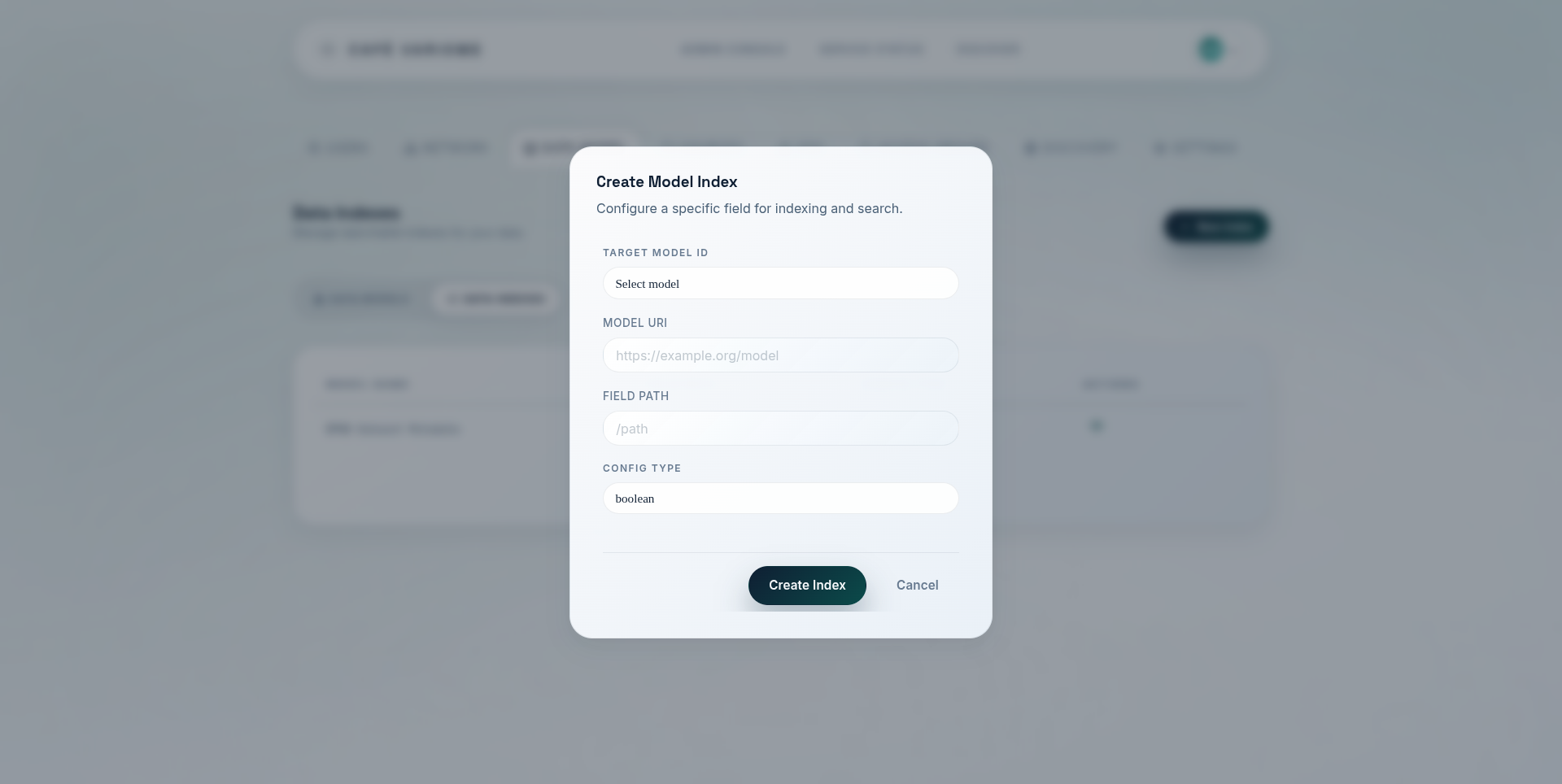
The available index types include:
- Boolean: A field that can only have two values, true or false.
- Enumerated: A field that can have a limited set of values. During indexing, the system will automatically extract the unique values from the data into a set. This set will be used to display the available options for querying this field in the discovery interface.
- Numeric: A field that contains numeric values. The system will automatically calculate the minimum and maximum values from the data, which can be used to display a range slider for querying this field in the discovery interface.
- Free Text: A field that contains free text. Free text fields are not just text: if the field is meant to be searched with keywords, partial string match or exact matches, there is no need to create a free text index. This type of index tells the system that the field is meant to be searched with full text search, and the system will create a full text index for this field in the database, either using ElasticSearch or a vector database. This enables semantic search and fuzzy matches for this field in the discovery interface. However, this is noticably slower during query time, because the query string must be processed first. It will also use much more resources during indexing. For simple fields like names, keywords, or categorical variables, it is recommended to use normal text search. Only use free text index for long text fields that are descriptive in nature.